Web Scraping in Ruby with Mechanize
In many cases data can be collected from a website/online service via an API. When an API isn’t available or the data isn’t quite what you want then an alternative method for acquiring that data is web scraping. This is typically done with code that simulates human web surfing to collect specified bits of information from websites. Ruby is an elegant language that has a vast repository of open-source tools or ‘Gems’. There are several Gems capable of handling web scraping such as Nokogiri, Capybara (typically used for coding test sequences but can also handle scraping) and Mechanize. Mechanize is developed by the same team as Nokogiri. It has Nokogiri as a dependency and therefore has all of its capabilities. It also has features related to web automation (such as the capability to fill out and submit forms). For these reasons, Mechanize is a great all-in-one web scraping and automation tool.
The Mechanize website describes the tool as follows:
The Mechanize library is used for automating interaction with websites. Mechanize automatically stores and sends cookies, follows redirects, and can follow links and submit forms. Form fields can be populated and submitted. Mechanize also keeps track of the sites that you have visited as a history.
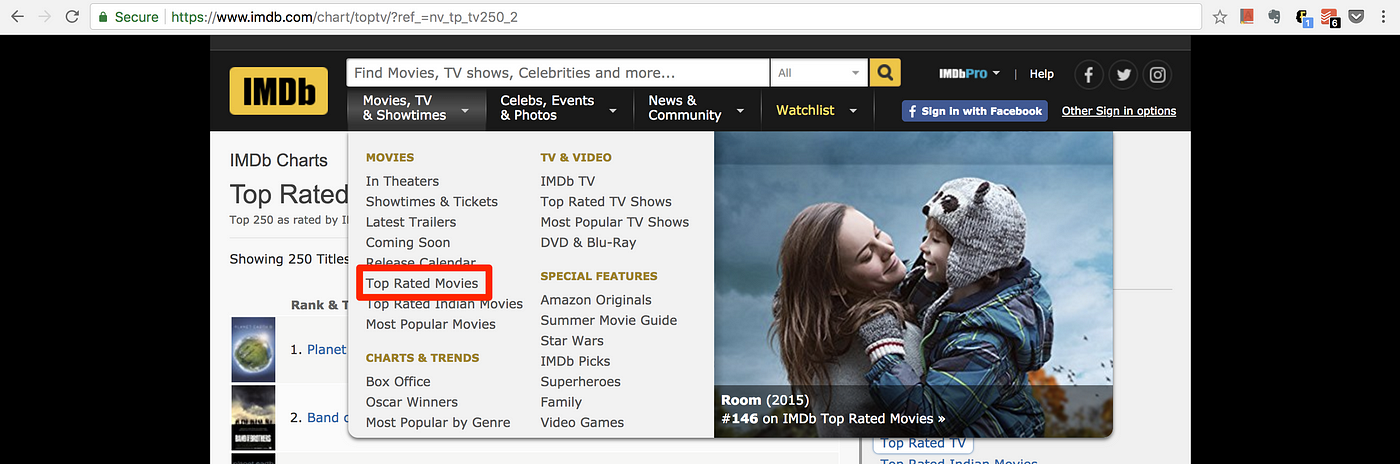
In order to show Mechanize’s capabilities I decided to try and scrape the top 250 movies from the IMDB website. This is accessed from the home page via the drop-down link called “Top Rated Movies” as highlighted below.
To start, install the Mechanize and Pry Gems by typing the following into the terminal. Pry is optional but useful. If you’re unfamiliar with pry its a tool that is used for debugging. It creates a breakpoint wherever binding.pry is written in the code and is therefore useful for digging into iterations and understanding the Mechanize syntax.
gem install mechanize pryLet’s start the code as shown below. We create a new instance of the Mechanize class and set it equal to agent. We then use the get request on agent with the URL for the IMDB homepage and set it equal to page.
page generates a large dataset but all we want from this is the link to the top rated movies.
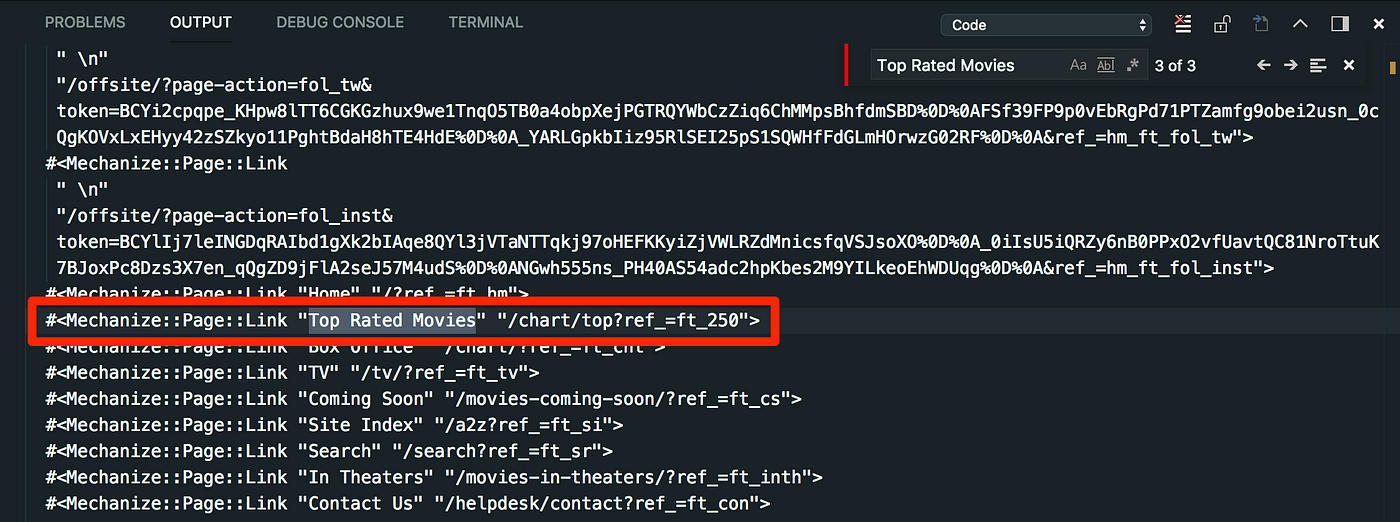
Mechanize has a link method which extracts only URLs from the large dataset. There are then additional methods we can perform on each link such as display the link text or its URL.
We want to find the specific link for the ‘Top Rated Movies’ URL. It therefore makes sense to use the find iterator. Once the link has been found we can use the resolved_uri method to display the URL for this link. After successfully locating the link to the top rated movies we can use Mechanize’s click method to open the page.

If you were to pp page at this point the result would once again be a large, messy dataset. If you scroll through the results until the point where the movies start to appear you’ll see that a pattern starts to develop. The URLs for the top 250 movies all contain the term chttp_tt… within the URL. We can use this to filter out the links from page that are only related to the top 250 movies. before each movie entry there is a common string (" \n") which also has the same URL extension. We want to exclude this from our filtered results.

The code below is all that stands between you having a large, indecipherable dataset and a clean array with all of the movie names!
I started by setting movies to an array of all the page links. These page links are Mechanize link instances. We can therefore use all of the useful Mechanize link methods on this data. Before iterating over the movies array I created an empty array called top_250_movies to shovel the results into. I then use the map iterator to take each link, convert the URL to a string, and check to see if it includes the common string identifier. If that returns a value of true I then check to see if it is equal to “ \n” so that I can exclude it if it is. If both if statements return true then I shovel the link text into the array.
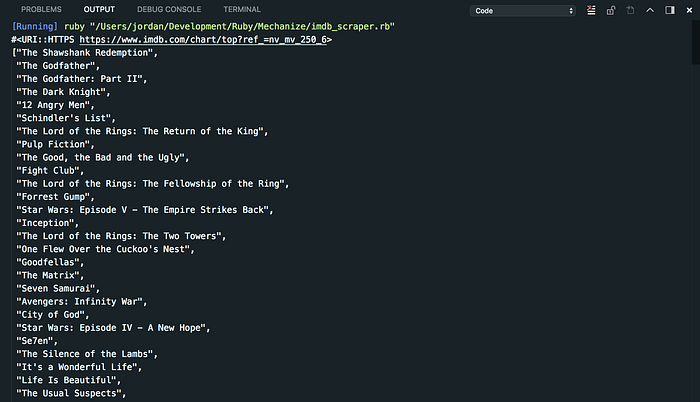
The final array is exactly what we want! It has a length of 250 and it is ordered within the array by the index within the top movies list. This simple exercise shows how incredibly powerful Mechanize is. It can be used to extract complex data from almost any website which can then be easily utilized in your own applications.